《上海交通大学学报》

陈丹琦关系抽取新SOTA;上海交大医疗版MNIST数据
来源:上海交通大学学报 【在线投稿】 栏目:综合新闻 时间:2020-11-10机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文包括上海交大发布的医疗版 MNIST 数据集,以及陈丹琦在关系抽取方面的新探索。
目录:
MedMNIST Classification Decathlon: A Lightweight AutoML Benchmark for Medical Image Analysis
A Survey on Multi-source Person Re-identification
Combining Label Propagation and Simple Models out-performs Graph Neural Networks
A Frustratingly Easy Approach for Joint Entity and Relation Extraction
Self-training and Pre-training are Complementary for Speech Recognition
A Survey on Contrastive Self-supervised Learning
Image Sentiment Transfer
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:MedMNIST Classification Decathlon: A Lightweight AutoML Benchmark for Medical Image Analysis
作者:Jiancheng Yang、Rui Shi、Bingbing Ni
论文链接: AI 技术的发展中,数据集发挥了重要的作用。然而,医疗数据集的创建面临着很多难题,如数据获取、数据标注等。近期,上海交通大学的研究人员创建了医疗图像数据集 MedMNIST,共包含 10 个预处理开放医疗图像数据集(其数据来自多个不同的数据源,并经过预处理)。和 MNIST 数据集一样,MedMNIST 数据集在轻量级 28 × 28 图像上执行分类任务,所含任务覆盖主要的医疗图像模态和多样化的数据规模。
它在全部 10 个数据集上评估 AutoML 算法的性能,且不对算法进行手动微调。研究人员对比了多个基线方法的性能,包括早停 ResNet [6]、开源 AutoML 工具(auto-sklearn [7] 和 AutoKeras [8]),以及商业化 AutoML 工具(Google AutoML Vision)。研究人员希望 MedMNIST Classification Decathlon 可以促进 AutoML 在医疗图像分析领域的研究。
 MedMNIST 数据集概览,涵盖数据集的名称、来源、数据模态、任务和数据集分割情况。
MedMNIST 数据集概览,涵盖数据集的名称、来源、数据模态、任务和数据集分割情况。
研究人员对比了多个基线方法的性能。
 算法在规模较小的数据集上容易过拟合。
算法在规模较小的数据集上容易过拟合。
推荐:上海交大研究人员创建新型开放医疗图像数据集 MedMNIST,并设计「MedMNIST 分类十项全能」,旨在促进 AutoML 算法在医疗图像分析领域的研究。
论文 2:A Survey on Multi-source Person Re-identification
作者:YE Yu、WANG Zheng、LIANG Chao 等
论文链接: 趋近成熟。然而,目前的研究多基于一个相对理想的假设,即行人图像都是在光照充足的条件下拍摄的高分辨率图像。因此 虽然大多数的研究都能取得较为满意的效果,但在实际环境中并不适用。多源数据行人重识别即利用多种行人信息进行行 人匹配的问题。除了需要解决一般行人重识别所面临的问题外,多源数据行人重识别技术还需要解决不同类型行人信息与 一般行人图片相互匹配时的差异问题,如低分辨率图像、红外图像、深度图像、文本信息和素描图像等。因此, 与一般行人重 识别方法相比,多源数据行人重识别研究更具实用性,同时也更具有挑战性。
本文首先介绍了一般行人重识别的发展现状和 所面临的问题,然后比较了多源数据行人重识别与一般行人重识别的区别,并根据不同数据类型总结了 5 类多源数据行人 重识别问题,分别从方法、数据集两个方面对现有工作做了归纳和分析。与一般行人重识别技术相比,多源数据行人重识别 的优点是可以充分利用各类数据学习跨模态和类型的特征转换。最后,本文讨论了多源数据行人重识别未来的发展。
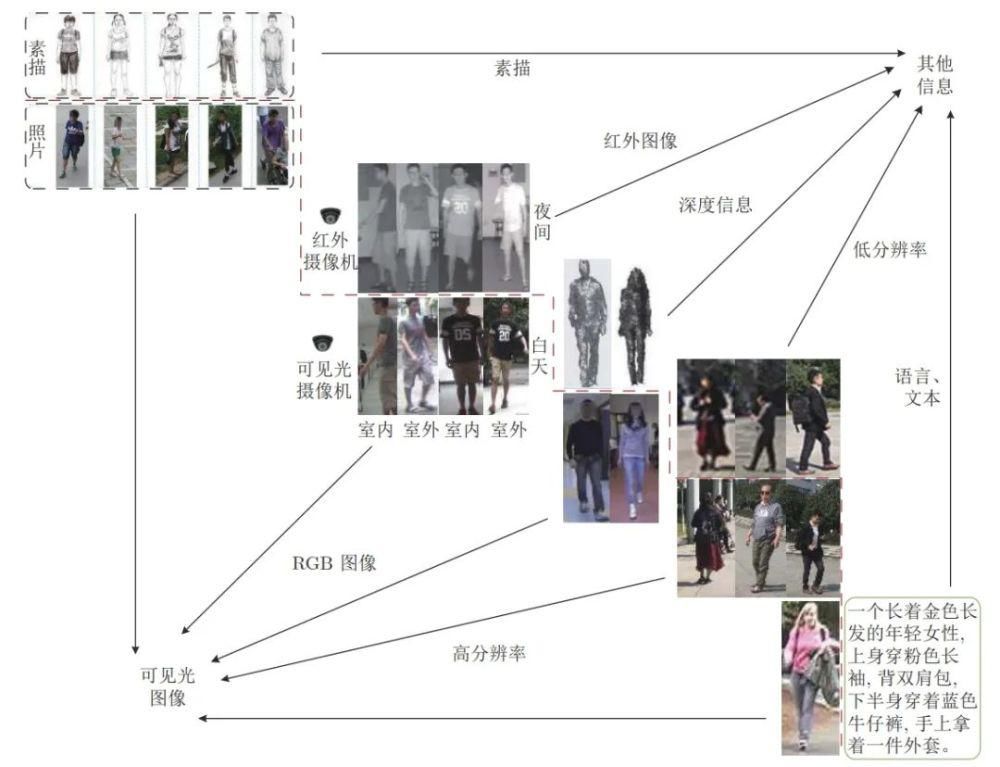 多源数据行人重识别类型。
多源数据行人重识别类型。
 三类多源数据行人重识别方法描述。
三类多源数据行人重识别方法描述。
 几种多源数据行人重识别方法在常用的行人数据集上的识别结果。
几种多源数据行人重识别方法在常用的行人数据集上的识别结果。
推荐:这项研究在《自动化学报》上发表。
论文 3:Combining Label Propagation and Simple Models out-performs Graph Neural Networks
作者:Qian Huang、Horace He、Abhay Singh 等
论文链接: GNN 成功的奥秘以及它们对于优秀性能是否必然知之甚少。近日,来自康奈尔大学和 Facebook 的一项研究提出了一种新方法,在很多标准直推式节点分类(transductive node classification)基准上,该方法超过或媲美当前最优 GNN 的性能。
这一方法将忽略图结构的浅层模型与两项简单的后处理步骤相结合,后处理步利用标签结构中的关联性:(i) 「误差关联」:在训练数据中传播残差以纠正测试数据中的误差;(ii) 「预测关联」:平滑测试数据上的预测结果。研究人员将这一步骤称作 Correct and Smooth (C&S;),后处理步骤通过对早期基于图的半监督学习方法中的标准标签传播(LP)技术进行简单修正来实现。